Hadoop이 버전1에서 버전2로 올라갔지만, 두 버전 모두 MapReduce 엔진을 주요 모듈로 가지고 있다.
MapReduce도 HDFS와 비슷한 방식으로 Job을 제출하고, Job의 진행 상황을 추적하는 로직을 가지고 있다.
네임노드가 있는 서버에는 잡 트래커(Job Tracker)가 있고,
데이터노드가 있는 장비에는 태스크 트래커(Task Tracker)가 배치된다.
비슷하게 잡 트래커는 여러 태스크 트래커에 효율적으로 임무를 할당하고, 결과를 수신하여 병합하는 역할을 한다.
하지만 MapReduce 엔진은 Hadoop 0.23버전에서 대폭 변경이 된다.
그래서 MapReduce 2.0 혹은 MRV2라고 불렀었는데,
나중에 YARN(Yet Another Resource Negotiator)이라는 이름이 지어졌다.
(yarn은 '실'이라는 뜻이 있어서, YARN을 표현할 때 털실뭉치를 많이 사용한다)
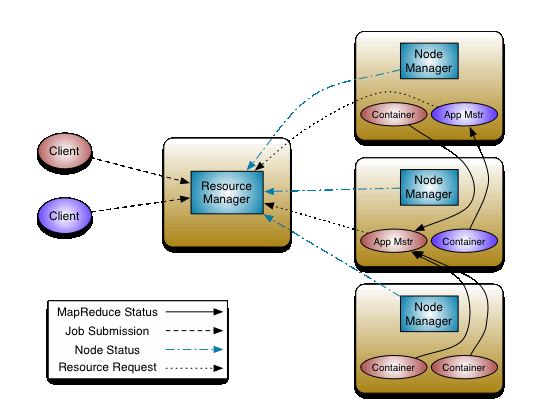
YARN은 기존의 Job Tracker를 리소스 매니저(Resource Manager)와 어플리케이션 마스터(Application Master)로 분리하였다.
리소스 매니저들은 클러스터 내의 컴퓨팅 리소스들을 어플리케이션에 할당해 주는 역할을 한다.
어플리케이션 마스터는 컴퓨팅 리소스를 할당받아 어떤 어플리케이션을 실행하고, 라이프 사이클을 관리한다.
이 어플리케이션은 전통적인 MapReduce 뿐 아니라, 다른 형태의 것도 가능해서 훨씬 더 융통성이 생겼다.
정리하면 리소스 매니저는 장비마다 있는 노드 매니저(Node Manager)를 통해 리소스를 관리하고, 어플리케이션 마스터는 어플리케이션 마다 할당되어 생성되며, 리소스 매니저와의 협상을 통해 실제 컴퓨팅 리소스를 사용한다.
이러한 변화는 아래의 Hadoop 스택을 통해서도 볼 수 있다. 즉 이제 MapReduce는 유일한 프로세싱 방법이 아니라, DAG(Directed Acyclic Graph, 방향성 비순환 그래프)로 일반화된 프로세싱 방법 위에서 돌아가는 하나의 어플리케이션일 뿐이다.

결론적으로 YARN은 Hadoop의 클러스터 컴퓨팅 파워를 더 향상시켰다.
확장성 : 매우 큰 동적인 클러스터를 효율적으로 관리할 수 있다
호환성 : YARN은 기존의 MapReduce 어플리케이션과의 하위 호환성을 제공한다. 그래서 Hadoop 1.0에서 작성된 프로그램은 Hadoop 2.0에서도 동작한다.
효율성 : 클러스터의 각 장비의 컴퓨팅 능력을 최대로 활용하여, 컴퓨팅 용량을 증가시켰다.
다양한 워크플로우 지원 : MapReduce 뿐 아니라 그래프 프로세싱, 반복(Iterative) 모델링, 머신러닝 등의
다른 워크 플로우도 지원한다.
'Hadoop ecosystem > YARN' 카테고리의 다른 글
| YARN과 MapReduce (0) | 2018.04.11 |
|---|---|
| 노드 매니저 구성 요소 (0) | 2018.04.10 |
| 리소스 매니저 구성요소 (0) | 2018.04.10 |
| YARN 구조 (0) | 2018.04.10 |