Hadoop Version 1
JobTracker 혼자 모든 자원들을 관리한다. 그렇기 때문에 JobTracker가 죽으면 클러스터위의 모든 어플리케이션들은 죽어버린다. 그리고 클러스터에 많은 어플리케이션이 붙으면 JobTracker는 병목현상을 일으켜서 성능이 급격히 저하된다. 이러한 이슈 때문에 Yarn(Yet Another Resource Negotiator)가 Hadoop 2.0부터 탑재되었다.
Hadoop Version 2
Yarn의 기본 아이디어는 JobTracker이 감당했던 일인 자원 관리와 job Scheduling / monitoring을 서로 나누는것이다.
이를 감당하는 컴포넌트들은 ResourceManager와 ApplicationMaster(AM), NodeManager 등으로 나뉜다.
Resource Manager 는 기본적으로 순수하게 하둡 클러스터의 전체적인 리소스 관리만을 담당하는 심플한 모듈이다.
현재 가용한 리소스들에 대한 정보를 바탕으로 이러한 리소스들을 각 애플리케이션에 일종의 정책으로서 부여하고 그 이용 현황을 파악하는 업무에 집중한다.
Application Master 는 Resource Manager 과 협상하여 하둡 클러스터에서 자기가 담당하는 어플리케이션에 필요한 리소스를 할당받으며, 또한 Node Manager 과 협의하여 자기가 담당하는 어플리케이션을 실행하고 그 결과를 주기적으로 모니터링한다. 자기가 담당하는 어플리케이션의 실행 현황을 주기적으로 Resource Manager 에게 보고한다.
Application Master 의 정확한 정의는 특정 프레임워크 (MapReduce, Storm 등 다양한 어플리케이션) 별로 잡(Job)을 실행시키기 위한 별도의 라이브러리이다. 예를 들면, 기존의 MapReduce는 MapReduce Application Master 에서, 기존의 스트리밍 처리는 스톰(Storm) Application Master 에서 각자 담당하고 책임을 지게 된다.
즉, 특정한 어플리케이션의 처리 라이브러리를 Application Master 에 올림으로써 하나의 하둡 클러스터에서 다양한 어플리케이션이 돌아 가도록 하는 것이 핵심이다. 이러한 구조의 변화에 의해서 사용자는 데이터의 속성에 맞는 다양한 어플리케이션을 처리하는 별도의 Application Master 을 만들어서 확장시킬 수 있다.
아래 그림과 같이 Hadoop 1.0에서 data processing과 cluster resource management를 모두 감당해야했던 MapReduce에서 Yarn이 cluster resource management를 감당 해줌으로써 MapReduce는 data processing만 수행하면 되게 되었다. 이로써 1.0에서 생기던 병목현상이나, 하나의 JobTracker가 감당해야했던 일들을 여러 컴포넌트들이 분담하게 됨으로써 성능을 향상시킬 수 있었다.
또한, 기존의 MR어플리케이션 프로그래머들은 data processing을 위해 기존의 코드(MRv1)를 변경하지 않아도 되며, 기존의 코드 그대로 Application Master를 통하여 실행하게되면 아래계층에서 Yarn을 통하여 데이터에 효율적으로 접근이 가능하게된다.
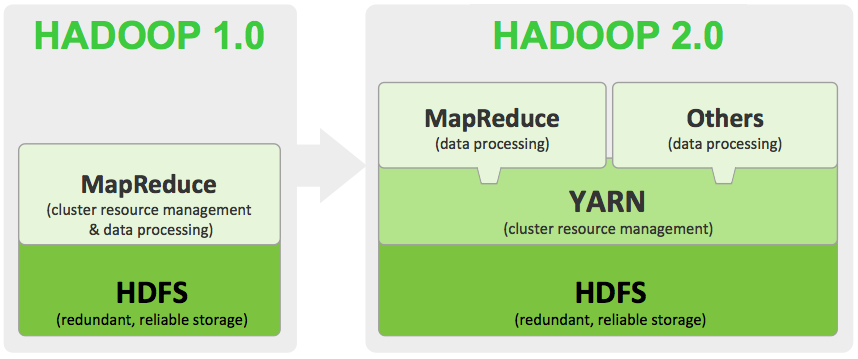

참고 : https://stackoverflow.com/questions/31044575/mapreduce-2-vs-yarn-applications
http://skccblog.tistory.com/1884
'Hadoop ecosystem > YARN' 카테고리의 다른 글
| 노드 매니저 구성 요소 (0) | 2018.04.10 |
|---|---|
| 리소스 매니저 구성요소 (0) | 2018.04.10 |
| YARN 구조 (0) | 2018.04.10 |
| YARN 개념 (0) | 2018.04.10 |