MapReduce연산이 진행되는 DataFlow에 대해 살펴 보겠습니다.

1. Input Files
MapReduce Task를 위한 데이터는 inputFile에 저장되어 있습니다. 그리고 이 input file은 HDFS에 저장 되어있습니다. 이 파일의 포맷은 임시적이며, line-based log files 과 binary format 을 사용할 수 있습니다.
2. InputFormat
InputFormat은 input file이 어떻게 분할되고 어떻게 읽어지는 가를 정의합니다.
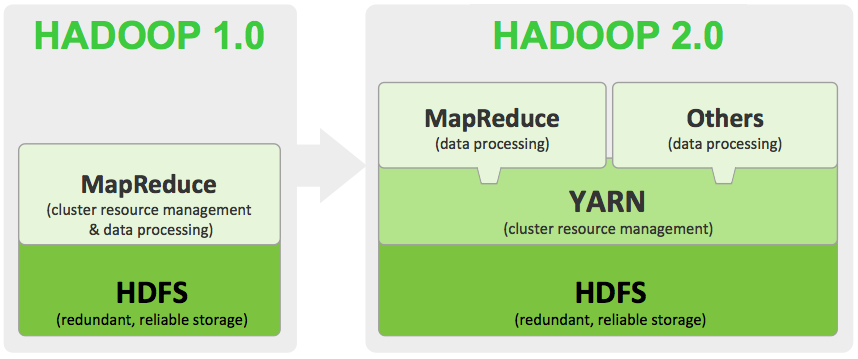
Hadoop의 Job은 Map task와 Reduce task로 나누어집니다.
그리고 이 task들은 Yarn에 의해 스케쥴링되고 클러스터안의 노드위에서 실행됩니다. 만약 task가 fail되면 자동으로 다른 노드로 rescheduling합니다.
InputFormat은 입력을 위해서 파일이나 다른 객체를 선택하여 getSplits()를 통하여 List<inputSplit>을 생성합니다. inputSplit를 Application Master에 전달하면 Map Task가 createRecordReader()를 실행시켜 RecordReader를 만듭니다.
Hadoop은 각각의 Split마다 하나의 MapTask를 생성하게 되는데, MapTask는 Split을 각각의 record로 나누어 사용자 정의 map Function을 적용합니다.
2.1. InputSplits
inputSplit은 inputFormat에 의해 생성되며, 데이터를 각각의 Mapper에 맞는 논리 형식으로 분할합니다. 예를들어서 HDFS의 File size는 128MB인데, 파일크기가 150MB라면 Block을 2개 읽어와서 논리적으로 시작과 끝을 지정합니다.
2.2. RecordReader
InputSplit에서 분할된 레코드들을 Mapper에 적합한 Key-Value쌍으로 변환합니다. 기본적으로 TextInputFormat를 사용하여 Key-Value쌍으로 변환합니다. InputFormat은 기본적으로 TextInputFormat를 지원하는데, TextInputFormat은 text file을 읽을때 \n까지를 한줄로 인식하고 한줄 단위로 Split을 만드는 기능을 합니다.
그리고 Record Reader은 InputSplit에서 유니크한 수인 byte offset을 키로하고, 각 라인을 value로 해서 하나의 새로운 Key-Value쌍을 만듭니다. 그리고 이 Key-Value쌍을 Data Processing을 위한 Mapper로 전송하게 됩니다.
3. Mapper
RecordReader를 통해서 입력된 record를 완전히 새로운 Key-Value쌍으로 만드는 프로세스 입니다. Mapper의해 발생된 출력은 HDFS에 바로 저장되지 않고 임시 데이터로 저장이고, 이 출력은 곧 Combiner에 입력으로 들어가게됩니다.
4. Combiner
‘Mini-reducer’라고 알려져 있는 Combiner는 Mapper의 출력을 local에서 Reduce를 처리합니다. local에서 각각에 대하여 reduce연산을 수행하게 되면 이후 진행되는 shuffling이나 Sorting Reducer작업을 위해 데이터를 전송할때 생기는 부하를 줄여주는 효과가 있습니다.
5. Shuffling and Sorting
Reduce에 입력으로 주기위해 Map연산이 끝난 데이터를 Reduce연산에서 생기는 네트워크 트래픽을 최소화 하기 위해서 Sorting하고 같은것으로 모으는 작업입니다.
6. Reducer
Mapper에 의해 생성된 key-Value쌍을 가지고 각각의 reduce연산을 통하여 최종 결과물을 출력합니다. 이 최종결과물은 HDFS에 저장됩니다.
7. RecordWriter
Reduce 연산이 끝난 Key-Value쌍을 출력 파일에 씁니다.
8. OutputFormat
OutputFormat에 의해 결정된 RecordWrite가 출력된 Key-Value쌍을 file에 씁니다. OutputFormat instances은 HDFS또는 그 local disk가 사용하는 하둡에의해 제공됩니다. reducer의 최종 출력은 OutputFormat instances에 의해 HDFS에 저장됩니다.
'Hadoop ecosystem > MapReduce' 카테고리의 다른 글
| WordCount (0) | 2018.04.14 |
|---|---|
| Indexing (0) | 2018.04.14 |
| InputType (0) | 2018.04.14 |
| MapReduce 3 (1) | 2018.04.09 |
| MapReduce프로그래밍을 위한 HL (0) | 2017.05.04 |