출처 : http://www.hellot.net/new_hellot/magazine/magazine_read.html?code=202&idx=29498
보안 문제, 여전히 해결해야 할 과제
최근 다양한 산업의 기술 혁신으로 대표되는 사물인터넷의 출현과 함께 자동차(혹은 커넥티드카), 의료 분야에서의 수요 증가로 임베디드 시스템 시장이 폭발적으로 성장할 것으로 전망된다. 한 시장조사기관은 글로벌 임베디드 시스템 시장이 2023년까지 연간 5.6%씩 성장하면서 2,587억 달러 규모를 달성할 것으로 예측했다. 그러나 기술 혁신으로 임베디드 시스템 간 연계되면서 발생할 수 있는 보안 문제는 해결해야 할 과제로 나타났다.
글로벌 임베디드 시스템 시장이 가파르게 성장할 것으로 보인다. 시장조사기관인 Radiant Insights가 발표한 보고서에 따르면, 2013년 1,403.2억 달러였던 이 시장은 연간 5.6%씩 성장하면서 2023년에는 2,587.2억 달러에 이를 전망이다(그림 1). 이러한 성장 배경에는 최근 출현한 사물인터넷에 힘입어 자동차와 의료 분야에서 임베디드 시스템에 대한 수요가 급증할 것으로 전망되기 때문이다. 보고서는 이 두 산업이 향후 임베디드 시스템 시장의 성장을 견인할 것으로 내다봤다.
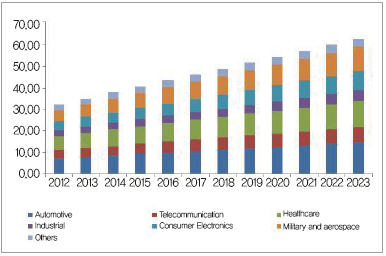
▲ 그림 1. 산업별 임베디드 시스템 시스템 시장 규모 (자료 : Radiant Insights)
임베디드 시스템은 마이크로프로세서 혹은 마이크로컨트롤러를 내장해 원래 제작자가 지정한 기능만을 수행하는 장치를 의미한다. 임베디드 하드웨어와 소프트웨어(OS, 소프트웨어)로 구성되며, 하드웨어는 프로세서/컨트롤러, 메모리, I/O, 네트워크를 포함하고, 임베디드 소프트웨어는 커널, 시스템 SW, 응용SW로 나뉜다. 보고서에 따르면, 2014년 임베디드 하드웨어는 시장 규모는 1,440억 달러로 사상 최대를 기록했다. 이 시장은 앞으로 연간 5.5%씩 성장하면서 2023년에는 2,400억 달러에 이를 것으로 예상됐다(그림 2). 특히, 러시아, 대만, 브라질, 인도, 중국과 같은 신흥 국가들이 산업 성장을 주도하는 새로운 기술들을 도입함으로써 이 기간 동안 임베디드 하드웨어의 수요 증가를 이끌 것으로 분석됐다.
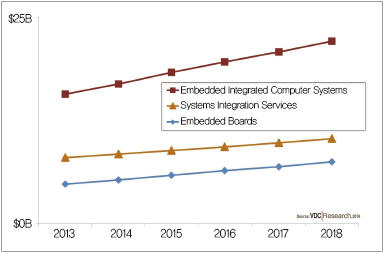
▲ 그림 2. 임베디드 하드웨어 시장 규모 (자료 : VDC Research)
이와함께 2014년 임베디드 소프트웨어 시장 규모는 95억 달러로 잠정 집계됐다. 보고서는 이 시장이 2023년에는 180억 달러 규모로 성장할 것이며, 가까운 미래에 IoT에 대한 수요가 폭발하게 될 경우, 임베디드 소프트웨어 산업 성장에 긍정적인 영향을 미칠 것으로 내다봤다.
자동차와 헬스케어, 임베디드 시장 성장 견인
이러한 임베디드 시스템은 현재 정보 가전, 정보 단말, 통신 장비, 항공/군용, 물류/금융, 차량/교통, 사무, 산업/제어, 의료, 게임, 로봇 등의 분야에서 활발하게 활용되고 있다. 그야말로 모든 산업에서 임베디드 시스템은 필수적인 요소가 됐다. 다양한 애플리케이션 중에서도 차량과 의료 분야가 임베디드 시스템의 가장 커다란 수요처가 될 것이란 전망이다.
2014년 전체 임베디드 시스템 시장 중 자동차가 22%를 차지했으며, 2013년 292.3억 달러였던 시장은 연간 6.7%씩 성장해 2020년에는 459.8억 달러에 이를 것으로 예측됐다. 가파른 성장의 배경으로 자동차와 도로의 통신과 효과적인 탐색 기능을 제공하기 위해 스마트 차량에서의 임베디드 시스템 도입이 늘어나고 있다. 또 배기 가스 규제라는 규율 준수를 위한 전기자동차 및 하이브리드 차량의 증가 역시 임베디드 시스템의 시장 성장 요인으로 지목됐다. 지금까지 동향을 보면 무선 통신 기술, 무선 통신, 디지털 처리 기술의 진보와 차량 내 전자 콘텐츠를 효율적으로 작동시키는 임베디드 시스템과 소프트웨어가 자동차 산업에서 크게 증가하고 있다.
자동차 한 대에는 A4 용지 400만장 분량의 임베디드SW가 내장된다고 한다. 전자제어장치(ECU)와 같은 40여대 컴퓨터가 1000여개의 반도체 칩을 작동 및 제어하며 최적의 주행이 이뤄지도록 자동적으로 조절한다. GSMA는 2018년 임베디드 시스템을 채택한 차량이 3,500만 대를 돌파해 전세계 자동차 판매량의 약 31%를 점유할 것으로 전망했다.
헬스케어 분야는 자동차에 이어 두 번째로 큰 임베디드 시스템 시장이다. 2020년까지 연간 7.1%씩 성장할 것으로 전망되고 있다. 사회 전반적으로 수명이 연장되고, 고급 의료기기 및 휴대용 의료기기의 수요가 증가되면서 임베디드 시스템 수요 역시 자연스럽게 늘어날 것으로 분석됐다. 일례로, ECG 신호 모니터링 모바일 임베디드 시스템, 혈당 모니터, 심박수 모니터 등과 같은 의료 장비의 도입이 증가하면서 임베디드 시스템의 수요 역시 늘어나고 있다.
북미, 점유율 1위 … 아태 지역 가파른 성장
임베디드 시스템 시장 규모는 어느 지역이 가장 클까? 보고서에 따르면, 2013년 임베디드 시스템 시장 규모가 가장 큰 지역은 북미로 전체 시장의 34.56%를 차지하는 것으로 조사됐다. 이 지역의 2015년도 시장 규모는 490억 달러로 집계됐고, 앞으로 연간 5.7% 씩 성장해 가면서 2023년에는 840억 달러에 이를 것으로 전망됐다. 유럽의 경우, 같은 기간 동안 5.3% 씩 성장해 620억 달러를 초과할 가능성이 있다고 봤다.
임베디드 시스템 시장에서 아태 지역은 핫 플레이스다. 가장 빠르게 성장하고 있다. 2014년 460억 달러였던 임베디드 시스템 시장 규모가 2023년에는 북미 시장과 어깨를 나란히 할 수 있는 810억 달러로 성장할 것으로 예측됐다. 이러한 급성장 배경에 대해 보고서는 아태 지역에서는 임베디드 시스템 전문가를 쉽게 구할 수 있고, 제조 공장이 밀집돼 있어 제조 비용을 절감하는데 있어 임베디드 시스템의 활용이 증가할 것이기 때문으로 분석했다.
복잡하긴 하지만 일반적으로 임베디드 시스템은 크게 마이크로컨트롤러/마이크로프로세서, 소프트웨어, 운영체제(OS)로 구분해 볼 수 있다.
임베디드 소프트웨어 엔지니어링 팀의 가장 중요한 결정 사항 중 하나는 어떠한 프로세서를 활용하느냐다. 프로세서의 선택은 임베디드 시스템의 특정 용도에 따라 다르지만, 일반적으로 전력 소모, 속도, 소프트웨어 지원, 메모리 등을 고려한다.
임베디드 시스템이 다양한 산업 분야로 확대됨에 따라 프로세서는 더욱 중요해졌다. 이 시장에서 프로세서 공급업체 간의 경쟁도 치열하다. (그림 3)을 보면, 텍사스 인스트루먼트(TI), 프리스케일, 그리고 마이크로칩이 임베디드 시스템 프로세서 시장의 거의 50% 이상을 차지하는 것을 볼 수 있다. 왜냐하면 이들 기업들이 공급하고 있는 다양한 프로세서들 때문에 점유율이 높다는 분석이다. 일례로, TI는 약 230여 종의 프로세서를 판매하고 있는 반면, 10여종을 판매하고 있는 기업도 있다. 따라서 임베디드 프로세서 분야에서 경쟁 우위를 갖기 위해서는 구매자의 특정 요구를 충족시킬 수 있는 폭넓은 다양성을 갖춰야 한다.
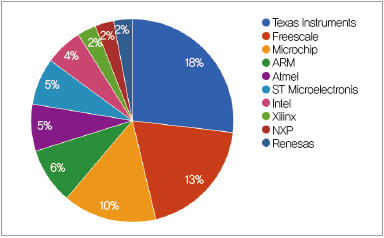
▲ 그림 3. 임베디드 시스템 프로세서 시장 점유율 (자료 : Embedded Dragon
Consulting)
임베디드 시스템의 프로그래밍 언어 시장은 오픈소스 언어가 지배하고 있다. (그림 4)에서 보듯, C/C++ 언어가 여전히 임베디드 시스템 시장에서 78% 이상을 차지하고 있다. 오픈 소스가 아닌 LavBIEW, MATLAB, .NET은 임베디드 산업에서 차별화된 기능을 가지고 조금씩 영향력을 확대해 나가고 있는 언어들이다.
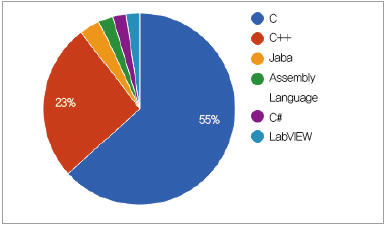
▲ 그림 4. 임베디드 시스템 언어 시장 (자료 : Embedded Dragon Consulting)
말할 필요도 없이 C/C++이 얼마 동안 임베디드 소프트웨어 개발자를 위한 프로그래밍 언어로써 가장 선호하는 경향이 지속될 것으로 전망되고 있다.
임베디드 시스템은 흔히 운영체제를 사용하지 않는 경우도 많으며, 사용한다 하더라도 윈도우 CE나 리눅스 등 임베디드에 맞춰진 운영체제나 실시간 운영체제(RTOS), 국방/항공용 실시간 운영체제(NEOS)를 사용해 자신의 새로운 시스템에 설정한다. 이는 대부분 임베디드 시스템의 경우 CPU나 메모리 자원 등의 구성이 일반 PC 등의 표준적인 플랫폼과는 달리 한계가 있는 시스템으로 일반 개인 컴퓨터용 운영체제를 사용할 수 없기 때문이다.
임베디드 프로그래밍 언어 시장과 유사하게 임베디드 시스템의 운영체제 분야도 크게는 오픈 소스가 우위를 점하고 있다. (그림 5)에서 보는 바와 같이 임베디드 시스템을 구현하기 위해 기업에서 공급하고 있는 운영체제를 구매하는 경우는 아주 드물다. 그 중에서도 마이크로소프트, 윈드 리버, Micrium, TI가 상업용 시장을 선도하고 있다. 그러나 모든 상업용 운영체제는 전체 운영체제 시장의 약 35%를 차지하는 반면, 오픈 소스 실시간 운영체제가 65%를 점유하고 있다.
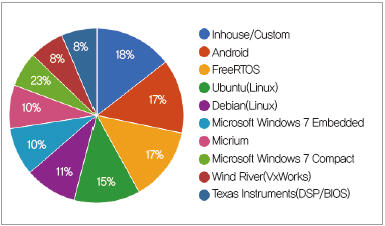
▲ 그림 5. 임베디드 운영체제 시장 점유율 (자료 : Embedded Dragon Consulting)
임베디드 성장 이면엔 보안 문제 도사려
모든 IT시장과 마찬가지로, 보안 문제가 임베디드 시스템 시장 성장의 발목을 잡을 수 있다는 시각이 많다. 우리 주변의 가전, 교통, 항공, 기계, 의료 장비, 자동차, 통신 장비 등이 대부분 임베디드 시스템에 의해 작동한다. 최근 모든 장비와 기계, 자동차 등은 OS, 웹서버, 리모트 콘트롤, 스마트 기기와 연결되는 추세다. 이러한 장비 중에서 의료 장비나 자동차 등은 보안 취약점을 통해 안전에 큰 영향을 미칠 수 있기 때문에 이에 대한 보안이 매우 중요하다.
허가받지 않은 소프트웨어 및 도난과 데이터 개인정보 보호와 같은 다른 취약점 문제에서 임베디드 시스템을 보호하는 것은 필수적이다. 이에 따라, 도난과 데이터 해커로부터 시스템을 보호하고, 이러한 문제들을 해결하기 위해 지속적인 노력이 이뤄지고 있다.