아래 CREATE INDEX 옵션들은 2008 기준입니다. 2008 이전 버전과는 사용법의 차이가 있으니 주의하세요.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | <relational_index_option> ::= { PAD_INDEX = { ON | OFF } | FILLFACTOR = fillfactor | SORT_IN_TEMPDB = { ON | OFF } | IGNORE_DUP_KEY = { ON | OFF } | STATISTICS_NORECOMPUTE = { ON | OFF } | DROP_EXISTING = { ON | OFF } | ONLINE = { ON | OFF } | ALLOW_ROW_LOCKS = { ON | OFF } | ALLOW_PAGE_LOCKS = { ON | OFF } | MAXDOP = max_degree_of_parallelism | DATA_COMPRESSION = { NONE | ROW | PAGE} [ ON PARTITIONS ( { <partition_number_expression> | <range> } [ , ...n ] ) ] } | cs |
1. PAD_INDEX & FILLFACTOR
- PAD_INDEX는 FILLFACTOR에서 지정한 인덱스의 채우기 비율을 사용할 것인지 여부를 결정합니다.
- FILLFACTOR는 1과 100 사이를 사용합니다.
혹 어떤 분들은 FILLFACTOR를 얼마나 사용해야 하는지 물어보시는 분들이 많은데요, 이것은 분석 여부에 따라 달라질 수 있습니다. 데이터 변경이 자주 일어난다면 숫자를 낮게 주고, 그렇지 않다면 높게 주어도 될 것입니다.
참고로, Oracle의 PCT_FREE와는 정 반대의 개념입니다. PCT_FREE 는 얼마나 남겨둘 지를 결정하고, FILLFACTOR는 얼마나 채워둘 것인지를 결정합니다.
2. SORT_IN_TEMPDB
- 간단히 말해서 인덱스 생성을 tempdb에서 하고 그 최종본만 실제 인덱스에 반영하는 것입니다.
- 장점은 인덱스 생성속도가 적게 걸린다는 것이고, 단점은 tempdb 가 커진다는 것입니다.
3. IGNORE_DUP_KEY
- UNIQUE INDEX를 생성할 때 키 중복(UNIQUE)에 대한 검사 여부를 지정합니다.
- 사실 이 기능을 ON으로 하면 UNIQUE하지 않은 행만 실패하게 되므로… 사용하시지 않는 것을 권장합니다.
4. STATICS_NORECOMPUTE
- 통계를 다시 생성할 지 여부를 결정합니다. 기본값이 OFF인데요.
굳이 ON으로 해서 통계를 생성하지 않을 필요는 거의 없습니다.
5. DROP_EXISTING
- 인덱스를 전체적으로 삭제하고 다시 작성할 지 여부를 결정합니다. 기본값은 OFF입니다만,
인덱스 명명 규칙이 있을 경우 이미 기존 명칭이 있을 것이므로,
삭제하고 다시 생성하기 위애 ON 으로 주어야 합니다.
6. ONLINE
- 단순하게 바라보면, 인덱스 생성 중에 테이블을 사용할 수 있는지 여부를 지정하는 것이지만,
다시 말하자면, 인덱스를 작성하면서 TABLE LOCK을 걸지 않도록 합니다.
- SQL 2005부터 지원되면서 DBA들에겐 큰 힘을 주었던 옵션이며 기본값이 OFF이므로 사용하려면 ON 으로
별도 지정해 주어야 합니다.
7. ALLOW_ROW_LOCKS & ALLOW_PAGE_LOCKS
- 행이나 페이지 LOCK 여부를 결정하며 기본값이 ON입니다. 많이 사용하는 옵션은 아닙니다.
8. MAXDOP
- 테이블의 크기가 클 경우 부하를 줄이기 위해 CPU 병렬작업을 수행할 지 결정하며
CPU 개수 64라는 값까지 줄 수 있습니다.
- 참고로 Standard Edition은 지원하지 않습니다. \
엄밀히 따지면 평가판을 빼면 Enterprise Edition만 된다고 하는 편이 낫겠네요. ㅋ.
9. DATA_COMPRESSION / ON PARTITIONS
- DATA_COMPRESSION은 테이블을 압축하는 것과 같이 데이터 압축 여부를 선택합니다.
- ON PARTITIONS 옵션은 DATA_COMPRESSION 옵션을 사용할 때에만 적용됩니다.
- DATA_COMPRESSION 옵션은 NONE / ROW / PAGE 등의 옵션이 있습니다.
출처 : http://www.sqler.com/322711#1
'SQL > SQL 튜닝' 카테고리의 다른 글
| 쿼리변환 (0) | 2017.10.26 |
|---|---|
| 클러스터링 팩터 (0) | 2017.10.26 |
| 옵티마이저 이해하기 - 2 (0) | 2017.10.26 |
| MSSQL LOOKUP (0) | 2017.10.24 |
| 클러스터인덱스와 넌클러스터인덱스 (0) | 2017.10.24 |




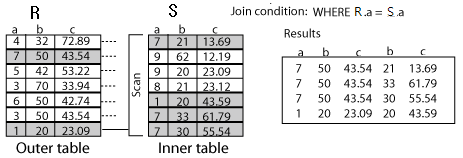
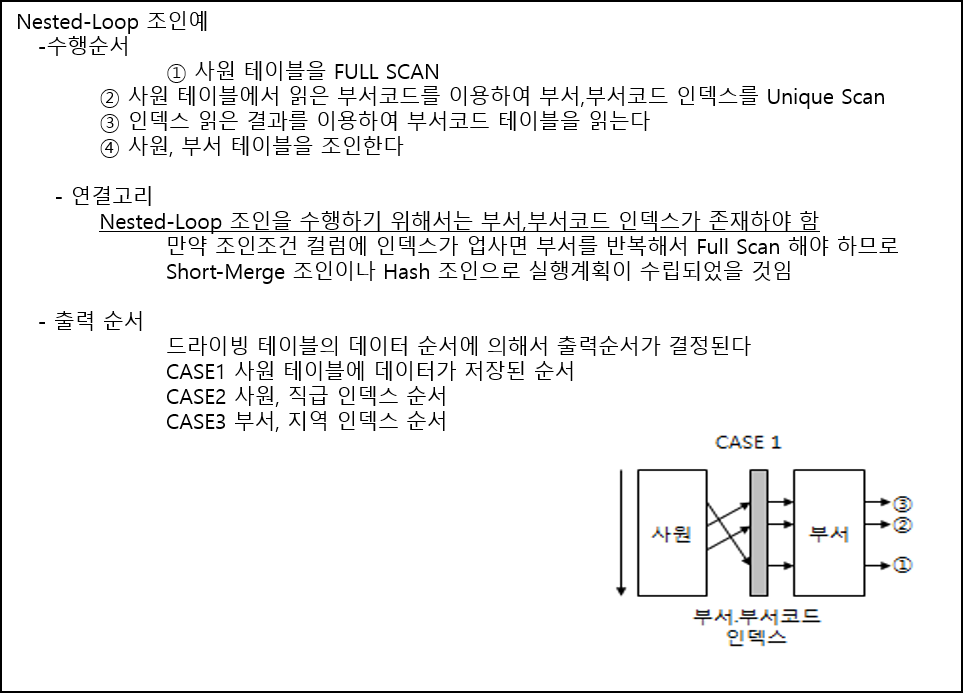
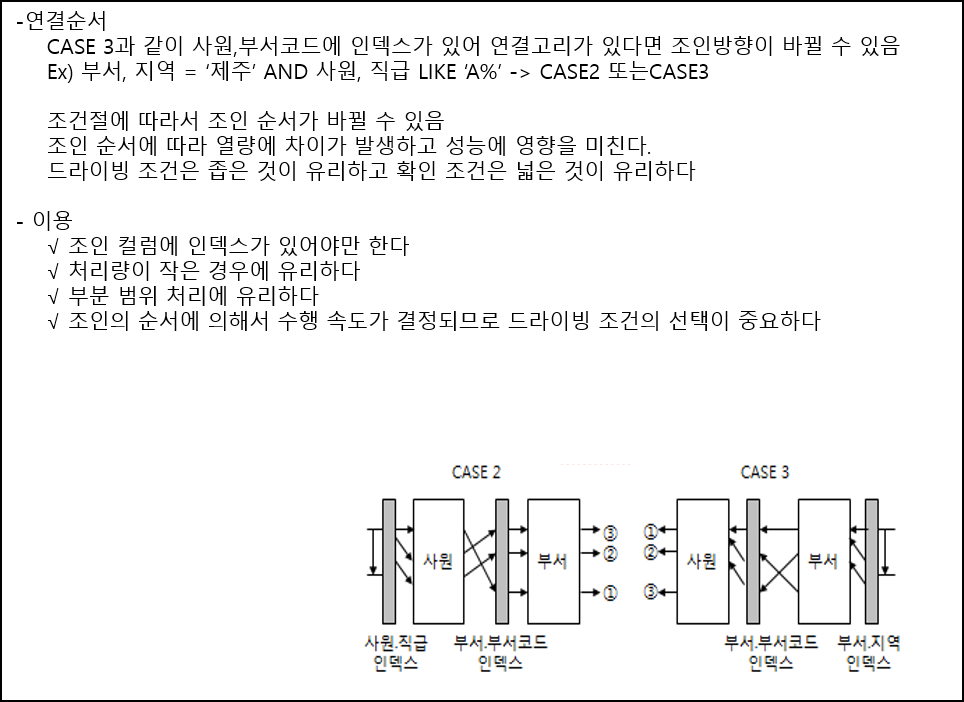
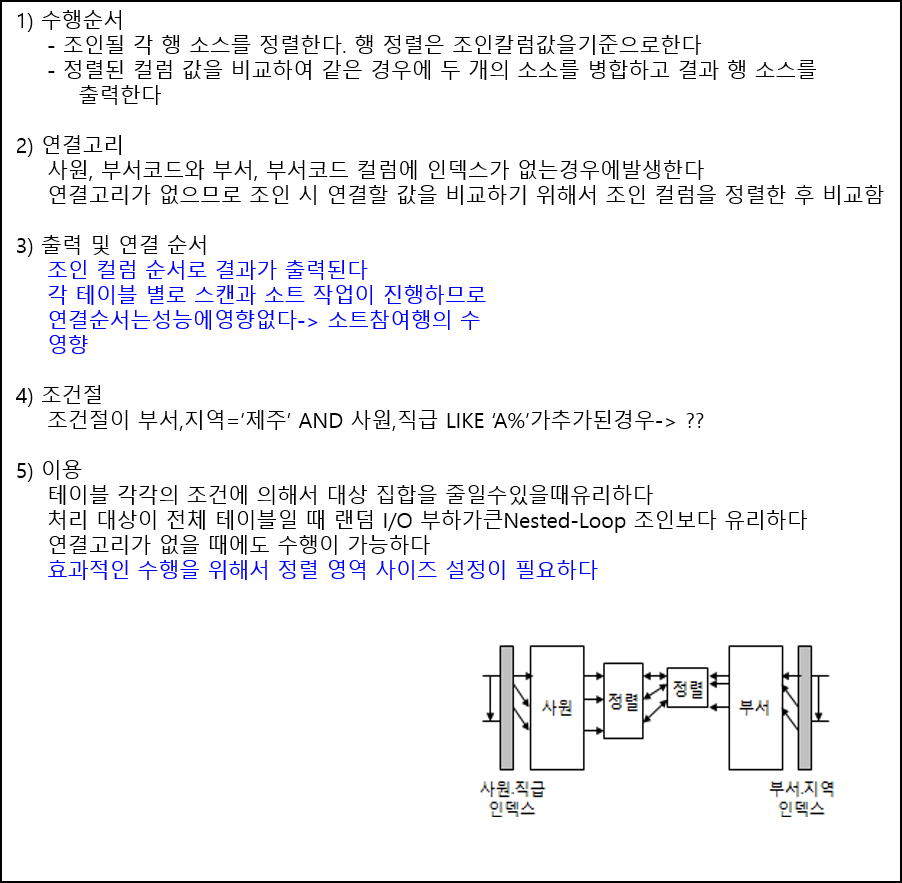
 A=B S 를 기준으로 설명함
A=B S 를 기준으로 설명함