방 법 | 설 명 |
중첩 반복 조인 (Nested Loop join) | 선행테이블(드라이빙 테이블)의 처리범위를 하나씩 액세스하면서 그 추출된 값으로 연결할 테이블(후행 테이블)을 조인하는 방식 |
색인된 중첩 반복 조인, 단일 반복 조인 (single loop join) | -후행(Driven) 테이블의 조인 속성에 인덱스가 존재할 경우 사용 - 선행 테이블의 각 레코드들에 대하여 후행 테이블의 인덱스 접근 구조를 사용하여 직접 검색 후 조인하는 방식 |
정렬 합병 조인 (Sort Merge join) | 양쪽 테이블의 처리범위를 각자 액세스하여 정렬한 결과를 차례로 scan하면서 연결고리의 조건으로 merge해 가는 방식 |
해시 조인 (Hash join) | 해시(Hash)함수를 사용하여 두 테이블의 자료를 결합하는 조인 방식 |
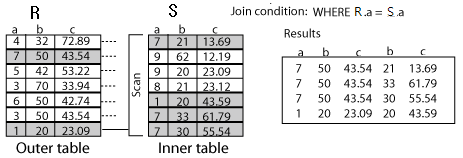
※ 아래의 조인 알고리즘들은 R  A=B S 를 기준으로 설명함
A=B S 를 기준으로 설명함
( 릴레이션 R과 S의 각 튜플들이 R의 A애트리뷰트와, S의 B 애트리뷰트 값이 일치하면 결합)
중첩 반복 조인(Nested Loop Join)
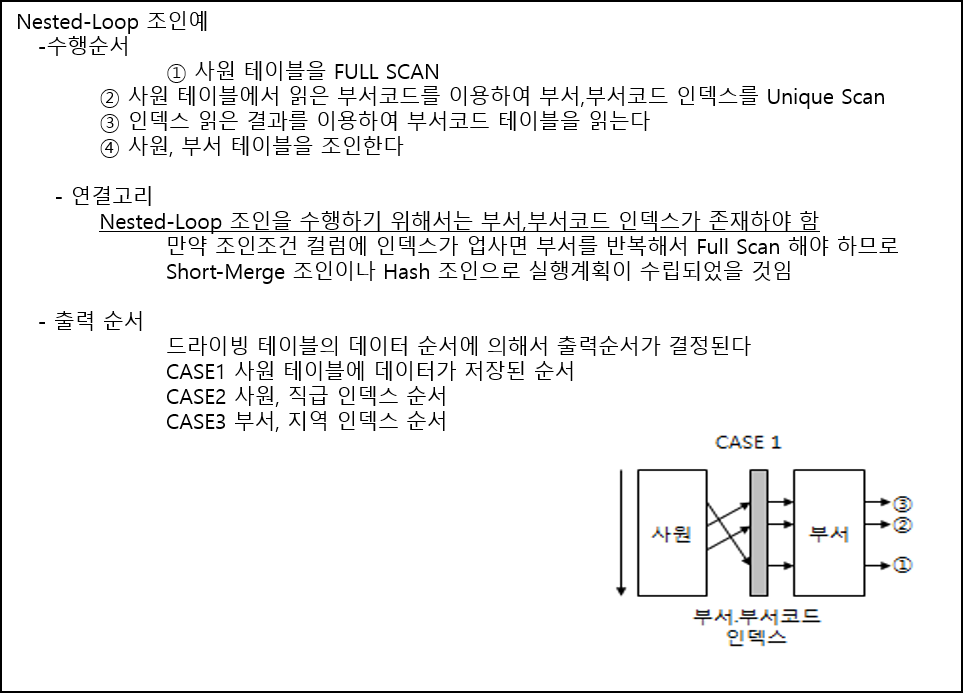
가. Nested Loop Join 알고리즘
- 2개 이상의 테이블에서 하나의 집합을 기준으로 순차적으로 상대방 Row를 결합하여 원하는 결과를 추출.
- R(외부, 선행 테이블)의 각각의 레코드에 대해 S(내부, 후행 테이블)의 모든 레코드를 검색하여, 두 레코드가 조인 조건(A=B)을 만족하는지 확인하여 만족하면 조인하는 방법
나. 색인된 중첩 반복 조인(=단일 반복 조인, single loop join) 알고리즘
- S(내부 테이블)의 B에 인덱스가 존재할 경우 사용
- R의 각 레코드들에 대하여 S의 인덱스 접근 구조를 사용하여 S의 레코드들 중에서 조인조건을 만족하는 레코드를 직접 검색
다. 사용법 및 사용예제
힌트: /*+ USE_NL(A B) */
select /*+ use_nl(b,a) */ a.dname, b.ename, b.sal
from emp b, dept a
where a.loc = 'NEW YORK'
and b.deptno = a.deptno
라. Nested Loop의 특징
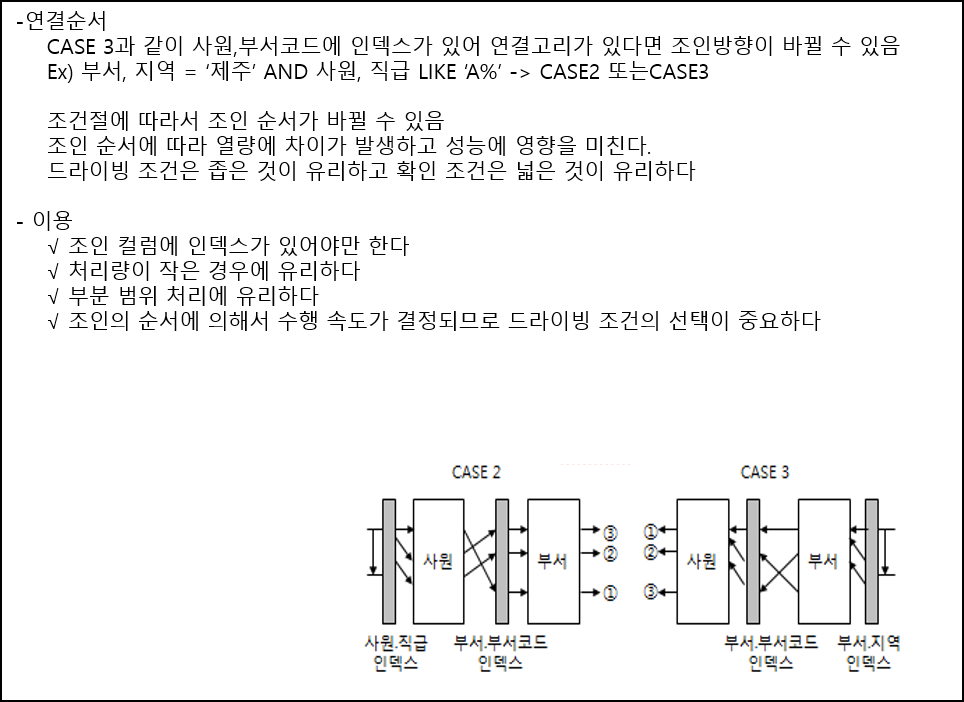
- 주로 좁은 범위에 유리
- 순차적으로 처리하며, Random Access 위주
- 후행(Driven) 테이블에는 조인을 위한 인덱스가 생성되어 있어야 함
- 실행속도 = 선행 테이블 사이즈 * 후행 테이블 접근횟수
마. Nested Loop사용 시 주의사항
- 데이터를 랜덤으로 액세스하기 때문에 결과 집합이 많으면 수행속도가 저하됨
- 선행(Driving) 테이블의 크기가 작거나, Where절 조건을 통해 결과 집합을 제한할 수 있어야 함
- 조인 연결고리 인덱스가 없거나, 조인 집합을 구성하는 검색조건이 조인 범위를 줄여주지 못할 경우 비효율적임
- Loop 개수를 줄이기 위해 조인에 참여하는 테이블 중 Row수가 적은 쪽을 Driving으로 설정하고, inner 테이블의 연결고리를 결합인덱스를 이용해 최적화함
바. Nested Loop사용 예
정렬 합병 조인(Sort Merge Join)
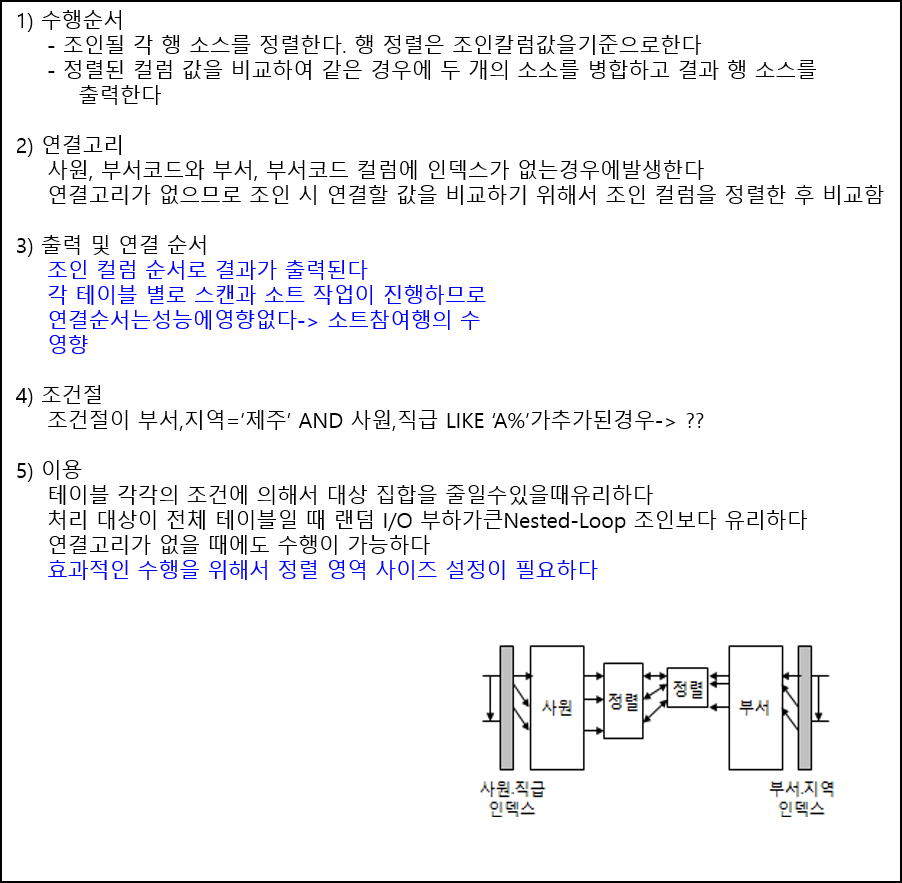
가. Sort Merge Join 알고리즘
- R과 S의 레코드들이 각각 조인 애트리뷰트 A, .B 값에 따라 물리적으로 정렬되어 있는 경우, 두 파일을 모두를 조인 애트리뷰트의 순서에 따라 동시에 스캔하면서 A, B 값이 동일한 레코드를 검색
- 정렬되어 있지 않은 경우는 우선 외부 정렬을 사용하여 정렬 후 조인
-조인의 대상범위가 넓을 때 발생하는 랜덤 액세스를 줄이기 위한 경우나 연결고리에 마땅한 인덱스가 존재하지 않을 때 해결하기 위한 대안
나. 사용법 및 사용예제
힌트: /* USE_MERGE(A B) */
select /*+ use_merge(a b) */a.dname, b.empno, b.ename
from dept a,emp b
where a.deptno = b.deptno
and b.sal > 1000 ;
다. Sort Merge Join의 특징
- 연결을 위해 랜덤 액세스를 하지 않고 스캔을 하면서 이를 수행
- 정렬을 위한 영역(Sort Area Size)에 따라 효율에 큰 차이가 남
- 조인 연결고리의 비교 연산자가 범위 연산(‘>’,’< ‘)인 경우 Nested Loop 조인보다 유리
라. Sort Merge Join사용시 주의사항
- 두 결과집합의 크기가 차이가 많이 나는 경우에는 비효율적
- Sorting 메모리에 위치하는 대상은 join key뿐만 아니라 Select list도 포함되므로 필요한 select 항목 제거
마. Sort Merge Join사용 예
해시 조인(Hash Join)
가. Hash Join 알고리즘
- 해싱 함수(Hashing Function) 기법을 활용하여 조인을 수행하는 방식으로 해싱 함수는 직접적인 연결을 담당하는 것이 아니라 연결될 대상을 특정 지역(partition)에 모아두는 역할만을 담당함
- R의 애트리뷰트 A와 S의 애트리뷰트 B를 해시 키로 하고, 동일한 해시 함수를 사용하여 해시
- 1단계(분할 단계, partitioning phase): 더 적은 수의 레코드를 가진 화일(R )의 레코드들을 해시 파일 버켓들로 해시
- 2단계(조사 단계, probing Phase): 다른 파일(S)의 각 레코드를 해시하여 R에서 동일한 해시 주소를 갖는 버켓 내의 레코드들이 실제로 조인 조건을 만족하면 두 레코드를 결합
나. 사용법 및 사용예제
힌트: /*+ USE_HASH(A B) */
select /*+ use_hash(a b) */ a.dname, b.empno, b.ename
from dept a, emp b
where a.deptno = b.deptno
and a.deptno between 10 and 20;
다. Hash Join의 특징
- Nested Loop 조인과 Sort Merge 조인의 문제점을 해결
- 대용량 처리의 선결조건인 랜덤 액세스와 정렬에 대한 부담을 해결할 수 있는 대안으로 등장
- Hash 조인만을 이용하는 것보다 parallel processing을 이용한 hash 조인은 대용량 데이터를 처리하기 위한 최적의 솔루션 제공
- 2개의 조인 테이블 중 small rowset을 가지고 hash_area_size에 지정된 메모리 내에서 hash table 생성
- Hash bucket이 조인집합에 구성되어 Hash 함수 결과를 저장하여야 하는데, 이러한 처리에 많은 메모리와 CPU자원이 소모됨
- CBO(Cost Based Optimizer) 모드에서 옵티마이저가 판단가능하며, 테이블의 통계정보가 있어야 함
- Hash table 생성 후 Nested Loop처럼 순차적인 처리 형태로 수행함
라. Hash Join사용시 주의사항
- 대용량 데이터 처리에서는 상당히 큰 hash area를 필요로 함으로, 메모리의 지나친 사용으로 오버헤드 발생 가능성
- 연결조건 연산자가 ‘=’인 동치조인인 경우에만 가능
마. Hash Join정리
1) 수행순서
- 두 테이블을 스캔하여 사이즈가 작은 테이블을 선행 테이블로 결정
- 선행 테이블을 이용하여 해쉬 테이블을 구성한다(Build Input)
- 후행 테이블은 해쉬 값을 이용하여 선행 테이블과 조인한다(Prove Input)
2) Build Input 크기
- Hash Area 만으로 Hash Table 생성이 불충분하다면 Hash Table Overflow가 발생
내Hash Area 사이즈를 증가 필요함
3) 이용
- 대용량 데이터 엑세스, 배치처리, 전체 테이블을 조인할 때 유리하다
- 양쪽 테이블의 조건으로 각각 범위를 줄일 수 있을 때 유리하다
- 병행 처리로 수행속도 향상이 가능하다
- Hash Area 사이즈 조정으로 수행속도 향상이 가능하다
조인 연산 비교
가. Nested Loop와 Hash Join의 비교
구분 | Nested loop join | Hash join |
대량의 범위 | 인덱스를 랜덤 액세스에 걸리는 부하가 가장 큰 문제점으로, 최악의 경우 하나의 ROW를 액세스하기 위해 Block단위로 하나하나 액세스를 해야 함. | 적은 집합에 대하여 먼저 해시 값에 따른 Hash Bucket정보를 구성한 후 큰 집합을 읽어 해시 함수를 적용하여 Hash Bucket에 담기 전에 먼저 호가인해 볼 수 있기 때문에 해시조인이 효율적인 수행이 가능 |
대량의 자료 | 다량의 랜덤 액세스 수행으로 인해 수행 속도가 저하 | 대용량 처리의 선결조건인 ‘랜덤 액세스’와 ‘정렬’에 대한 문제 개선과 H/W의 성능 개선을 통해 각 조인 집합을 한번 스캔하여 처리하기 때문에 디스크 액세스 면에서 훨씬 효율적 |
나. sort merge와 Hash join의 비교
구 분 | Sort merge join | Hash join |
조인이 되는 두 테이블의 크기가 다를 경우 | 조인이 되는 두 테이블의 크기가 다르다면 정렬되는 시간이 동일하지 않아 시간에 대한 손실이 발생 | 조인에 대한 알고리즘을 구현하기 때문에 두 집합의 크기가 차이가 나도 대기 시간이 발생치 않음 |
대용량 데이터의 경우 | 정렬에 대한 부담 때문에 sort merge조인은 제 기능을 발휘하지 못하는 경우가 발생. 즉 메모리 내의 지정한 정렬 영역보다 정렬할 크기가 지나치게 큰 경우 정렬할 범위가 넓어질수록 효율성을 하락 | 대용량 처리의 선결 조건인 ‘랜덤 액세스’와 ‘정렬’에 대한 문제 개선과 H/W의 성능 개선을 통해 각 조인 집합을 한 번 스캔하여 처리하기 때문에 디스크 액세스 면에서도 훨씬 효율적 |
출처 : http://www.jidum.com/jidums/view.do?jidumId=167
'SQL > SQL 튜닝' 카테고리의 다른 글
| MSSQL LOOKUP (0) | 2017.10.24 |
|---|---|
| 클러스터인덱스와 넌클러스터인덱스 (0) | 2017.10.24 |
| 옵티마이저 이해하기 - 1 (0) | 2017.10.23 |
| INDEX 튜닝 (0) | 2017.10.23 |
| 쿼리튜닝팁 (1) | 2017.09.20 |