이전 까지의 내용은 빅데이터 플랫폼 아키텍처에 대한 개요와 첫 걸음인 데이터 수집을 위한 다양한 오픈소스를 살펴보았습니다. 여러가지 오픈 소스 중에도 Apache Flume을 통한 정형,비정형 로그 수집, Apache Sqoop을 통한 DB 데이터 수집, 그리고, 데이터 저장을 위한 HDFS에 대해서도 간략히 알아봤습니다.
HDFS에 저장되어 있는 데이터를 효과적으로 처리하기 위한 오픈 소스 또한 여러가지가 있습니다. Map Reduce, Pig, Hive 그리고, 최근에 Hot 오픈 소스인 Spark 등이 있습니다.
Apache Pig와 Hive 비교
HDFS상의 데이터를 처리하기 위해 개발자가 개발언어(Java 등)로 직접 Mapreduce 코드를 작성하여 처리를 해왔다.
Pig가 나오면서 Pig Latin이라는 스크립트로 조금 더 쉽게 작성할 수 있었다. Mapreduce 코드보다 대략 1/20으로 코드량이 줄어들고, 개발속도 또한 1/16로 줄어든다는 통계도 있다. 하지만, Pig Latin 또한 스크립트이므로 개발자가 아니면 쉽게 접근하기 힘들 것이다.
이에 SQL 형태로 할 수 있게 된 것이 Hive이다. Database를 조작하는 SQL을 이해한다면, 쉽게 접근할 수 있게 되었다. 가장많이 선호하는 것이 Apache Hive라고 할 수 있겠다.
Pig와 Hive에 대한 요약과 차이를 간략히 정리된 내용을 소개하면 아래와 같다.
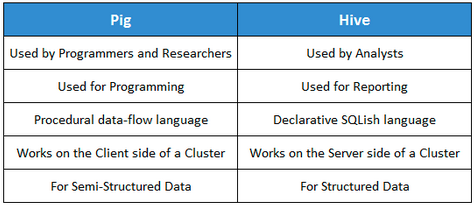
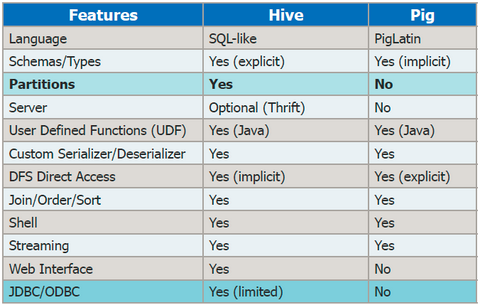
[출처 : http://www.edureka.co/blog/pig-vs-hive/ ]
about Apache Hive
여기서는 널리, 가장많이 사용되는 Hive에 대해서만 알아보고자 한다.
The Apache Hive ™ data warehouse software facilitates querying and managing large datasets residing in distributed storage.
Hive는 앞서 간단히 설명했듯이 HDFS 상의 오픈소스 DW 솔루션이다. DW(Data Warehouse)는 리포팅 및 분석을 위한 구조체라 보면 되겠다.
즉, Hadoop 클러스터에 저장된 데이터를 MapReduce 를 직접 구현하여 데이터를 분석 하기엔 개발 스킬과 경험이 필요하며, 이를 이해하고 구현 하는 시간과 노력을 줄이고자, 보다 편리하게 데이터 분석이 가능한 HIVE (SQL방식이며 facebook에서 개발) M/R 처리 기능을 도입되었다.쉽게 데이터를 ETL처리 할 수 있으며, HiveQL이라 부르는 ANSI-SQL을 지원하는 SQLike한 스크립트를 지원한다.
Hive Architecture는 아래와 같다.
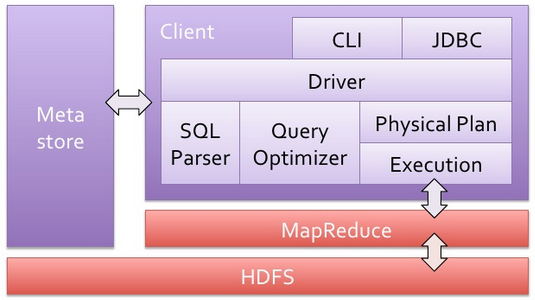
주요 구성요소를 보면,
- JDBC/ODBC : SQL Query문을 MR로 변환해주는 Query Compiler 및 실행엔진
- UDF/UDAF : 직접 필요한 함수를 만들어 사용할 수 있음
- Metastore
- HDFS상의 데이터를 DB Table 형식으로 관리하기 위한 메타 정보, table, patitions, column 정보를 저장.
- 임베디드 되어 있는 Apache Derby를 사용하거나, Local 또는 Remote의 RDBMS(MySQL, Postgres 등)를 Metastore로 사용할 수 있음.
아래 보는 바와 같이 HiveQL은 SQL을 알면 이용에는 무리가 없을 것이다.
1 2 3 4 5 6 | SELECT page_views.*
FROM page_views JOIN dim_users
ON (
page_views.user_id=dim_users.id
AND page_views.date >= '2015-07-24'
)
|
Hive 이용
- Hive 0.13.0 버전까지만 해도 Transactions이 지원되지 않았다. 즉, UPDATE, DELTE가 지원되지 않았음.
- 0.14.0 버전부터는 제한적이긴 하지만 Transactions이 지원된다. 하지만, BEGIN, COMMIT, ROLLBACK 는 지원되지 않는다. 즉, 항상 auto-commit 이다.
- Transcations 을 이용하기 위해서는 몇 가지 Configuration 조정이 필요하다. 해당 Configuration은 여기를 참조. – Hive Transactions
앞서 언급했듯이, HiveQL로 분석, 데이터 작업은 용이하나, 내부적으로는 어차피 Mapreduce 로 변환되어 진행되기 때문에 빠른 처리는 불가능하다. 그래서 최근에 많이 언급되고 있는 Facebook Presto, Tajo, Apache Spark 등 메모리 기반을 통해 성능, 속도향상을 하고 있다. 그 중에서도 최근에 가장 Hot한 것은 Apache Spark라고 할 수 있다.
Apache Spark
Hive와 호환이 되기 때문에 많이들 사용하고 있다. 아래 Spark 개요에서와 같이 Spark SQL -예전에 Shark라 불렀던-을 활용하면 쉽게 사용이 가능하다.
또한, 추천에 많이 사용하는 Machine Learning 오픈소스인 Apache Mahout를 대신해 최근에 Spark MLlib를 활용하는 추세이다.
Query에 따라 다르겠지만, Hive 비해 40배 정도 빠른 속도를 자랑한다.
또한, Spark Streaming을 통해 실시간 처리도 가능하다.
Hive와 Spark의 개념은 아래를 비교해보면 좀 더 이해가 쉬울 것이다.
Hive Architecture
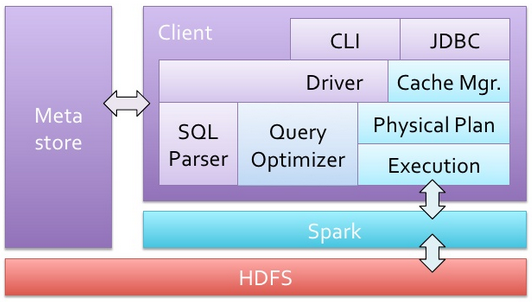
Spark Architecture
[출처 : http://www.slideshare.net/Hadoop_Summit/spark-and-shark]
Reference
출처 : http://hochul.net/blog/about-hive-pig-spark_data/
